- 发布于
- 约 34 分钟
打造本地 AlphaGo:RTX 5070 工作站装机与 KataGo 极限评测
- 作者

- 名称
- 宋元平
TL;DR: 两万元预算打造 RTX 5070 + Ultra 7 工作站,Katago 推理速度提升百倍,做成送给业余六段舅舅的 AI 神助手。
自从去年决定来 CMU 读 Master 之后,一直对 AI 的应用,尤其是本地部署很感兴趣。七月某日,逛r/localllama时突然联想到 - 之前大火过的 AlphaGo 也属于 AI 呀,不知道有没有开源,如果能在自己电脑上跑岂不有趣?可以借助 AI 的力量,来体验小学学围棋时没体验够的胜利喜悦 😆。简单搜索之后发现 AlphaGo 虽未开源模型(原版的模型需要在几百个 TPU 上运行,即使开源也没几个人可以用),但是真的有社区复刻的开源模型:Katago,而且相比原版模型更加压缩。得益于算法和硬件的进步,在消费级硬件上 Katago 现在可以流畅运行,超过人类最高水准。惊喜之余脑海里留下了一个种子。
2025 年五月回上海两周,思考了一下有什么有意义的礼物可以带给我五年未见,热爱围棋,业余六段的舅舅。遂决定为我舅舅装一台能运行 Katago 的工作站:即有意义,也满足一下我的装机愿望:)。
装机理念
既然决定 DIY,就一定要达到品牌机和组装机不一样的效果 (否则有被爸妈吐槽的风险 🙃)。DIY 潜在的优势是 1)相同预算达到比品牌机更高的配置; 2)用上比组装机更高品质的部件;3)针对自己的使用场景优化配置:只为自己需要的性能买单,并为未来升级预留空间。这些"潜在"的优势并不是自带的,需要认真设计才能充分发挥出来。如果需求仅仅是用最低价格买到某个配置(如 i7+5080),那一定是京东上的组装机比自己 DIY 便宜。
外设的重要性:我的目标给舅舅最好的使用体验而不是最高的跑分。外设对使用体验至关重要,因此预算也应该适当分配。
均衡性:这台电脑不仅跑 Katago,还需要跑各种日常任务。因此需要选择一个均衡的配置,满足未来~ 5 年的计算需求,而不是买一个最强的 GPU 就完事了。
系统层面的性价比:一台最具性价比的电脑不是由最具性价比的部件组成的,因为在衡量一个配件性价比的时候需要考虑到整台电脑的成本。举个例子:i9 比 i7 快 20%并贵 50%。 如果 i7 占整机成本的 25%,则升级到 i9 使整机成本增加 12.5%,但性能增加 20%。针对能把 i9 完全用上的使用场景,这个升级是完全值得的。
稳定性:因为我装完这台电脑以后就要回匹茨堡,没法解决售后问题,所以零部件尽量不能坏,至少也要方便保修,因此会倾向大厂成熟的产品。
具体硬件选择
CPU
坚定选择最新制程 2025 年还买 Intel 7 的芯片有点过于悲伤,在 14 代 Core 和 Ultra 2 之间果断选择采用 TSMC N3B 制程的 Ultra 2 系列。这样做的原因是和日常体验相关最大的单核核心性能非常依赖制程的进步。AI 工作站 打开网页的速度总不能比 Mac Mini 慢吧哈哈哈哈。
Ultra 5,7, 9? - 最有代表性的三款 Ultra 5 245, Ultra 7 265 和 Ultra 9 285 核心频率的区别可以忽略不计。主要的差异来自于核心数量。
CPU 型号 P-核心 E-核心 总核心数 总线程数 建议零售价 (MSRP) Ultra 5 245 6 8 14 16 $329 Ultra 7 265 8 12 20 28 $419 Ultra 9 285 8 16 24 32 $589 CPU 选择分析:为什么 Ultra 7 265 是最佳选择
分析要点
- • P-cores P-核心决定单线程性能,对日常使用体验最重要
- • KataGo KataGo 主要依赖 GPU,CPU 多核性能需求有限
- • Ultra 7 265 Ultra 7 265 在 P-核心数量和价格间达到最佳平衡
性价比分析:P-核心数 / 每$100价格
P-核心对于单线程性能最为重要,这个指标显示每花费$100能获得多少个P-核心。 悬停查看详细规格
CPU 选择分析:为什么 Ultra 7 265 是最佳选择 CPU P-核心 E-核心 总核心 总线程 价格 P-核心/$100 Ultra 5 245 6 8 14 16 $329 1.82 Ultra 7 265 8 12 20 28 $419 1.91 Ultra 9 285 8 16 24 32 $589 1.36 结论
Ultra 7 265 提供了 8 个 P-核心,比 Ultra 5 多 33%,但价格仅高 27%。相比 Ultra 9,拥有相同的 P-核心数量但价格便宜 29%,是性价比最优选择。
考虑到 KataGo 的推理主要依赖 GPU 性能,而不是 CPU 多核性能,Ultra 7 265 提供了最佳的性价比。Ultra 9 285 的额外 4 个 E 核心和更高的价格并不能为我们的使用场景带来明显的性能提升。同时,Ultra 5 缺少的两个 P 核心,因为这个架构不支持 SMT,在日常确实可能被需要到。
主板
选定 CPU 之后,主板是接下来选择范围最大的一个项目。适配 Ultra 2 芯片的 Z890/B860/M810 主板仅华硕就有近30 款,价格从 1000 到 5000。区别总结如下:
- 平台:Z890 (CPU+内存超频,雷电 5)> B860 (仅内存超频) > M810 (无超频支持)
- 系列:Maximus > Strix ≈ ProArt > Tuf > Prime
CPU 超频对于性能的提升非常有限(新一代 CPU 的基础频率已经很高了),因此选择放弃 CPU 超频。而很多 AI 应用(如 LLM 推理)瓶颈在内存带宽,因此内存超频的功能更加有用一些。M810 平台的主板,因为是超级性价比之选,功能砍得有点多,因此推荐折中的 B860 平台。
B860 主板选择:主板虽然相对于其他部件,对于性能的影响不大,但是由于所有的零件都需要安装在主板上。一块质量好的主板对于装机体验来说很有帮助。尤其是像我这样不是经常装机的选手 - 好的主板会有大量的防呆设计 - 接口只要能够安装上去,那就是正确的。接口也会比较牢固,在我暴力安装的过程中可以比较放心 😆。 还有一点是 CPU 基本上不会坏(酷睿 13,14 代除外 😆)相对而言主板属于消耗品。为几年前的 CPU 购买替换主板选择余地少,价格也不便宜(C620 主板坏了的痛 😭)。因此,如果机器想省心用久一点的话,应该搭配一块质量比较好的主板,然后祈祷他不要坏掉。出于这些考量,我选择了 B860 平台的旗舰 ROG STRIX B860-F GAMING WIFI。
显卡
- 运行 Katago 的显存占用只有 1G 左右,因此 50 系列和更古早的显卡都可以用。因为现在 GPU 溢价太高,所以选择入手了"够用就行"的 Prime RTX 5070 12G。
| 型号 | 显存容量 | FP16 Tensor TFLOPS(FP32 Accumulate) | 建议零售价(人民币) | 市场售价(人民币) |
|---|---|---|---|---|
| RTX 5090 D | 32 GB GDDR7 | 419.2 TFLOPS (Wikipedia, NVIDIA) | 16 499 元起 (IT 之家, Sina Finance) | 28 000 – 39 000 元 (36Kr, Sina Finance) |
| RTX 5080 | 16 GB GDDR7 | 225.1 TFLOPS (Wikipedia, ZOL AI) | 8 299 元起 (IT 之家, IT 之家) | ≈ 8 299 元 (IT 之家) |
| RTX 5070 Ti | 16 GB GDDR7 | 177.4 TFLOPS (Wikipedia, Sina Finance) | 6 299 元起 (Sina Finance, Sohu News) | 7 000 – 8 000 元 (Sohu) |
| RTX 5070 | 12 GB GDDR7 | 123.9 TFLOPS (Wikipedia, Gamersky) | 4 599 元起 (Gamersky) | ≈ 4 599 元 (什么值得买) |
| RTX 5060 Ti | 16 GB GDDR7 | 92.9 TFLOPS¹ | 3 599 元起 (SMZDM Post) | ≈ 3 400 元 (Zhihu) |
机箱
- 如果你已经看出本次装机是华硕主题的话不难猜到机箱会选择 PA401,这款和 PA602(我自己的服务器用了这款机箱)都非常推荐!做工很棒,风扇安静,安装过程也设计的很周到。
内存
- CPU 有两个内存通道,所以需要至少两条内存才能发挥全部性能。对于日常使用,内存够大的实用性大于极致的内存速度。32G 内存可以应对大部分需求,但既然是自己装机,就宽裕些,选择上到 64G,与主流配置拉开一些差距。在京东上比了下价选择了镁光 5600MHz 2x32GB 的内存套装。
SSD
- 主板和 CPU 都支持 M.2 Gen 5, 虽然预计在日常体验和 Gen 4 区别不大(开机快一秒钟?哈哈哈),但还是要尝尝鲜。无脑选择三星 9100 Pro.
电源
- 电源因为价格不高,而且更新换代慢,因此可以投资一个好一点的,方便以后更新显卡加装硬盘之类的。RTX 5070 需要最低 650W 的电源,上 850W 就可以比较安心。如果想为 5090 预留功率那就上 1000W。还有一个加分点是新标准电源(ATX3.1)有 600W 的 GPU 电源线,装机更加方便,否则需要拉两根电源线加转换器,稍显不够优雅。简单研究之后决定支持一下国产,入手 Thermalright 利民 SP850W 白金 ATX3.1。
散热器
- Ultra 7 265 的功耗不高,只有 65w(不打算超频),原装散热器基本够用。但是看到合适的款式还是入手了一个:1)为了外观 2)用大个的散热器风扇速度可以维持在很低,更加安静。很多散热器没有明确写适配 LGA1851,所以选择面不是很大。研究了一番后入手了 Thermalright 利民 Peerless Assassin 120。实测适配 LGA1851 没有问题。
显示器
- 习惯了苹果之后,对于屏幕素质的要求明显提高了哈哈哈。这次装机的备选项是两款戴尔今年 CES 推出的新款 32 寸 4k 屏幕:U3225QE 和 S3225QC。体验过后的感受是:两个屏幕都很赞!U3225QE 哑光屏看上去很舒服,接口很强大,非常适合连接笔记本做 dock + 一天八小时办公。S3225QC 亮面屏+OLED 色彩很漂亮,空间音频的扬声器也很惊艳,很适合连台式机作为影音屏。决定是 U3225QE 留下来自用,S3225QC 送给舅舅。参数对比如下:
| 参数 | S3225QC | U3225QE |
|---|---|---|
| 型号 | S3225QC | U3225QE |
| 屏幕尺寸 | 31.6 英寸 | 31.5 英寸 |
| 分辨率 | 3840×2160 | 3840×2160 |
| 面板类型 | QD-OLED | IPS Black |
| 刷新率 | 120 Hz | 120 Hz |
| 对比度 | 理论无限 : 1 | 3,000 : 1 |
| 响应时间 | 0.03 ms (GtG) | 5 ms (GtG) |
| 色域覆盖 | 99 % DCI-P3 | DCI-P3 99 % / sRGB 100 % |
| HDR 认证 | VESA DisplayHDR True Black 400 | DisplayHDR 600 |
| 扬声器 | 内置 5×5 W | 无内置扬声器 |
| USB-C 供电 | 最⾼ 90 W | 最⾼ 140 W |
| 端口 | 2×HDMI 2.1, 1×DisplayPort 1.4, 1×USB-C (DP+PD) | 1×HDMI 2.1, 2×DisplayPort 1.4 (输⼊), 1×DisplayPort 1.4 (输出), 2×Thunderbolt 4 (上/下⾏), 1×USB-C (KVM 上⾏), 4×USB-A, 1×2.5 GbE RJ45, 1×3.5 mm 音频输出 |
| 市场售价(人民币) | ¥ 6,499 | ¥ 5,999 |
预算:主机+外设 ¥20000 左右
配置清单
| 部件 | 型号名称 | 预算占比 |
|---|---|---|
| 显示器 | Dell S3225QC (31.6 英寸 4K QD-OLED 120Hz) | 31.0% |
| 显卡 (GPU) | ASUS PRIME RTX 5070 12G | 24.1% |
| CPU | Intel Core Ultra 7 265 | 12.3% |
| 主板 | ASUS ROG STRIX B860-F WIFI | 9.6% |
| 内存 (RAM) | Crucial 英睿达 64GB (2x32GB) DDR5 5600MHz | 6.2% |
| 固态硬盘 (SSD) | Samsung 三星 9100 PRO 1TB PCIe 5.0 NVMe | 5.3% |
| 键鼠 | Logitech 罗技 ALTO KEYS K98M + MX Master 3S | 4.8% |
| 电源 (PSU) | Thermalright 利民 SP850W 白金 ATX3.1 | 3.0% |
| 机箱 | ASUS 华硕 ProArt 创艺国度 PA401 (木艺铁韵版) | 2.9% |
| CPU 散热器 | Thermalright 利民 Peerless Assassin 120 (PA120) | 0.9% |
预算分配:¥20,000 工作站装机
预算洞察
- • 显示器占最大份额 (31%),体现用户体验优先
- • GPU + CPU 占 36.4% - 性能基础
- • 其余组件分配均衡,避免性能瓶颈
| 组件 | 占比 |
|---|---|
| 显示器 — Dell S3225QC (31.6 英寸 4K QD-OLED 120Hz) | 31% |
| 显卡 — ASUS PRIME RTX 5070 12G | 24.1% |
| 处理器 — Intel Core Ultra 7 265 | 12.3% |
| 主板 — ASUS ROG STRIX B860-F WIFI | 9.6% |
| 内存 — Crucial 英睿达 64GB (2x32GB) DDR5 5600MHz | 6.2% |
| 固态硬盘 — Samsung 三星 9100 PRO 1TB PCIe 5.0 NVMe | 5.3% |
| 键鼠 — Logitech 罗技 ALTO KEYS K98M + MX Master 3S | 4.8% |
| 电源 — Thermalright 利民 SP850W 白金 ATX3.1 | 3% |
| 机箱 — ASUS 华硕 ProArt 创艺国度 PA401 (木艺铁韵版) | 2.9% |
| 散热器 — Thermalright 利民 Peerless Assassin 120 (PA120) | 0.9% |
悬停在图表上查看详细组件信息
预算策略
此分配优先考虑用户体验(显示器),同时确保强劲性能(GPU/CPU)。其余组件的均衡分布创造了一个全面的系统,没有明显的薄弱环节。
Windows 上 Katago 安装指南
想愉快的使用 Katago 需要搞定几个组件:1)Katago 命令行程序 2)Katago 模型权重 3)Katrain 图形界面(如果对性能需求不高,可以跳过前面步骤,直接安装 Katrain 使用自带的 OpenCL 后端。愿意折腾 TensorRT 后端能再快 2.5 倍)。
一步一步来:
先从 Github 上下载最新版的 Katago 程序,根据操作系统和使用的加速库/后端有不同的下载选项。英伟达 GPU 性能最强的后端是 Tensor RT。用 Windows 可以下载 katago-v1.16.0-trt10.9.0-cuda12.8-windows-x64.zip 。以下是不同后端的对比:
可执行文件名称 平台 后端 构建对应版本 说明 katago-opencl Linux、Windows OpenCL — 通用 GPU 加速,无需特定驱动 (GitHub, Zhihu Column, CSDN Blog) katago-cuda12.5 Linux、Windows CUDA 12.5 针对安装了 CUDA 12.5 驱动的 NVIDIA GPU 进行优化 (GitHub, Zhihu Column, CSDN Blog) katago-trt10.2.0 Linux、Windows TensorRT 10.2.0 在支持 TensorRT 10.2.0 的 GPU 上拥有最高吞吐率 (GitHub, Zhihu Column, CSDN Blog) katago-cpu Linux、Windows Eigen — 纯 CPU 回退版本,无需 GPU 即可运行 (GitHub, Zhihu Column, CSDN Blog) katago-cpu-avx2 Linux、Windows Eigen AVX2 — 针对支持 AVX2 指令集的 CPU 进行优化 (GitHub)
从命名中可以发现需要搭配 TensorRT 10.9.0 和 CUDA 12.8 (其实 CUDNN 也需要,不然跑不了)。这非常有做 AI 的感觉了 😆。
安装 Visual Studio, 社区版本即可。运行英伟达的库需要用到 Visual Studio 提供的 DLL 文件。
从英伟达网站下载 CUDA Toolkit 安装包。CUDA 向后兼容所以即使安装了比 CUDA 12.8 更新的版本也没有关系。
CUDA 安装成功后安装 CUDNN
注意安装完 CUDNN 后需要把以下文件从 CUDNN 文件夹复制到 CUDA 的安装目录:
bin\cudnn*.dll (including cudnn64_9.dll)→C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\vX.Y\bininclude\cudnn*.h→C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\vX.Y\includelib\cudnn*.lib→C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\vX.Y\lib
更新系统环境变量
- 按下 Win + R,输入 sysdm.cpl 并回车,打开系统属性。
- 切换到 "高级" 标签页,点击 "环境变量"。
- 在 "系统变量" 中找到并选择 Path,点击 "编辑"。
- 点击 "新建",添加以下路径:
- C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\vX.Y\bin
- 再次,确保将 vX.Y 替换为您的实际 CUDA 版本。
- 点击 "确定" 保存更改,并关闭所有对话框。
在命令提示符里运行
where cudnn64_9.dll确保 CUDNN 可以被其他程序调用
安装 TensorRT,先从这里下载, 然后按照以下步骤(文档):
下载 TensorRT 压缩包
- 访问 NVIDIA TensorRT 下载页面
- 选择适用于 Windows 的版本,例如:
TensorRT-10.x.x.x.Windows.win10.cuda-11.8.zipTensorRT-10.x.x.x.Windows.win10.cuda-12.9.zip
- 下载后,将压缩包解压到您选择的安装目录,解压后会生成一个名为
TensorRT-10.x.x.x的子目录。
说明:
10.x.x.x表示 TensorRT 的版本号。cuda-x.x表示对应的 CUDA 版本,例如 11.8 或 12.9。
添加 TensorRT 库文件到系统 PATH
您可以通过以下两种方式之一将 TensorRT 的库文件添加到系统的环境变量 PATH 中:
方法一:添加解压目录中的 lib 路径到 PATH
- 按下 Windows 键,搜索并打开 "编辑系统环境变量"。
- 在弹出的窗口中,点击 "环境变量…"。
- 在 "系统变量" 部分,找到并选择 "Path",然后点击 "编辑…"。
- 点击 "新建",添加以下路径:
<安装目录>\TensorRT-10.x.x.x\lib - 连续点击 "确定",直到所有窗口关闭。
方法二:将 DLL 文件复制到 CUDA 安装目录
- 将
<安装目录>\TensorRT-10.x.x.x\lib目录中的所有.dll文件复制到您的 CUDA 安装目录,例如:
C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\vX.Y\bin其中
vX.Y是您的 CUDA 版本号,例如v11.8。 2. CUDA 安装程序通常会自动将其 bin 目录添加到系统的 PATH 中。安装 TensorRT 的 Python 包
- 打开命令提示符或终端。
- 导航到
<安装目录>\TensorRT-10.x.x.x\python目录。 - 使用 pip 安装适用于您 Python 版本的
.whl文件,例如:
python.exe -m pip install tensorrt-*-cp3x-none-win_amd64.whl将
cp3x替换为您的 Python 版本,例如cp310表示 Python 3.10。
此时 Katago 已经安装完毕,可以移步下载模型权重:https://katagotraining.org/networks/
- 任何模型都可以下载,绿色高亮的是当前最强模型。模型前缀表示模型架构(如:kata1-b28c512nbt)。架构越大的模型上限越高,但其实随便哪个模型都足够强了。
找到第一步下载的 Katago 程序和第 6 步下载的 Katago 模型权重,运行性能测试验证安装成功
.\katago.exe benchmark -model "权重的路径"
Katrain 图形界面
Katrain 是一个为 Katago 设计的图形界面,从 Github 上下载安装程序:Katrain.exe
安装成功后启动,单击左上角菜单按钮,打开"通用和引擎设置"界面。把"KataGo 运行文件路径"和"KataGo 模型文件路径"更新为在第 1 步和第 6 步下载的文件。"KataGo 引擎设置"中"分析中每步棋运算步数"可以从默认值增加。
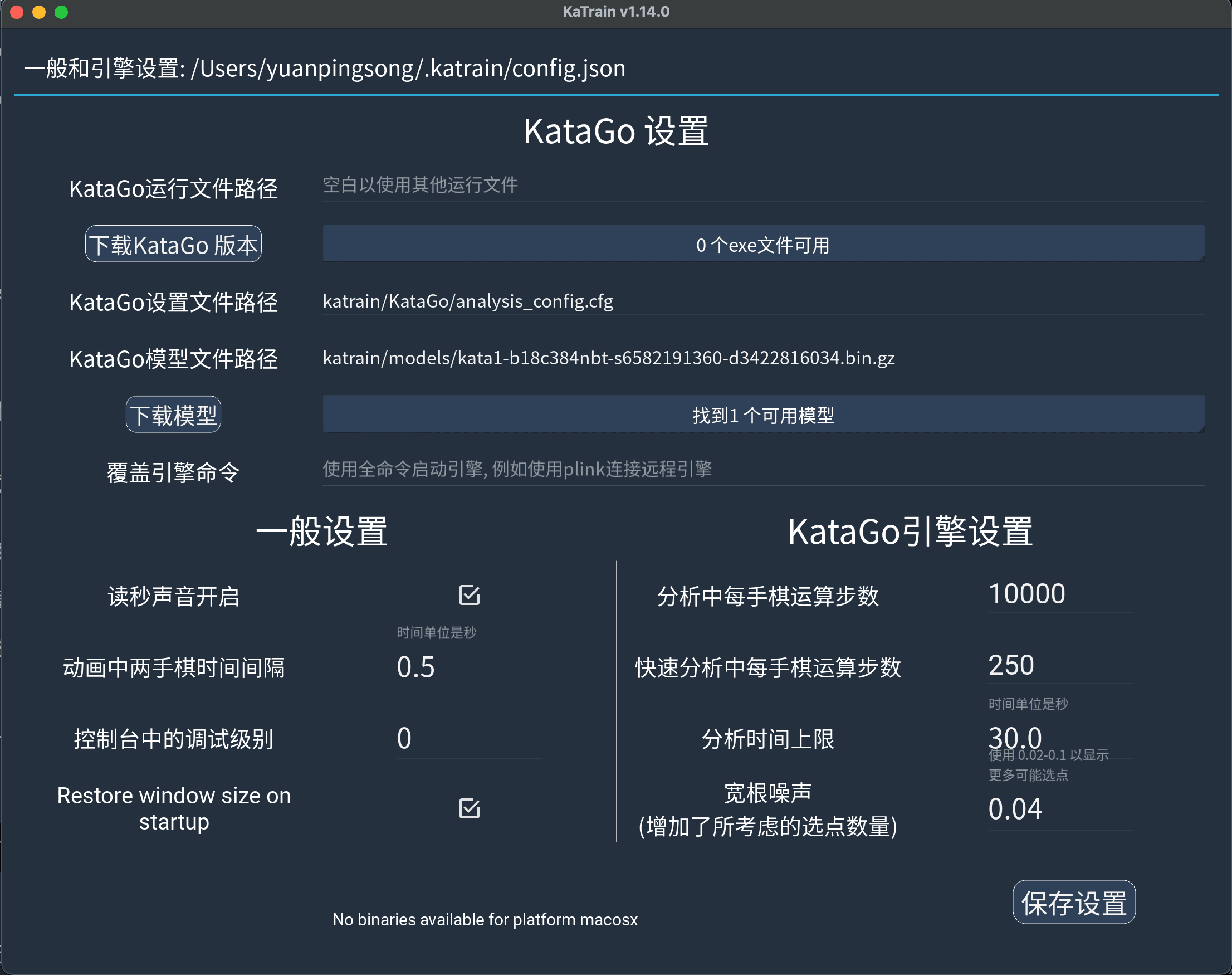
Katrain 设置界面:配置 KataGo 可执行文件路径和模型文件路径

Katrain 主界面:功能丰富的围棋分析工具
回到主界面,所有的安装就大功告成啦。下面是 Katrain 的实际使用演示:
Katrain 使用演示:实时围棋分析和 AI 对弈功能展示
Katago 性能评测
Katago 有不同架构(大小)的模型,最新推出参数最多的 b28c512 系列实力最强。但上一代的 b18c384 模型效率占优,能相同时间内能测试更多变化,适合在硬件性能有限的情况下对比多种下法的优劣。
虽然官方 Readme 已经提前剧透 TensorRT 是目前性能最强的后端,但是在 50 系列 GPU 上究竟对于 OpenCL 和 CUDA 有多大优势没有具体说明。虽然通用后端也能用,但英伟达的 TensorRT 到底能带来多大提升?这直接关系到老黄软件护城河的坚实程度。CPU 和 GPU 哪家跑 CNN 更快毫无悬念,但 CPU 是不是在要求不高的情况下也够用了呢?带着这两个好奇,我把所有的后端都用两种网络架构测了一遍。
还有一个疑问是 Katago 究竟多少个访问数够用,我让 Chatgpt 总结了一下发现结果其实挺惊人的 - Katago 不需要很多算力就可达到超人类的水准了。这还是根据 2020 年版的模型总结的,2024 年甚至有网友说最新模型一次访问就可以达到 8 段水平。堆更多访问量的意义对学习围棋来说主要在于可以分析棋盘上其他下法的优劣。
| 段位水平 | 建议访问次数 / 步† | 主要依据 | 注释 |
|---|---|---|---|
| 4 段 | ≈ 6 visits | portkata 校准公式 (2020) (GitHub) | — |
| 5 段 | ≈ 8 visits | 同上 (GitHub) | 博主常用"8 次"作 5d 练习 |
| 6 段 | ≈ 10 visits | 同上 (GitHub) | — |
| 7 段 | ≈ 12 visits | 同上 (GitHub) | — |
| 8 段 | ≈ 14 visits | 同上 (GitHub) | — |
| 9 段 | ≈ 16 visits | 同上;实测能击败 Zen7 9d (GitHub) | |
| 顶业余 / 准职业 | ≈ 128 visits | OGS 讨论:几十~百次已超最强业余 (Online Go Forum) | b28c512 额外 +300 Elo (Reddit) |
| 超人类 | ≥ 2 048 visits | OGS「潜在段位膨胀」& 对抗策略论文 (2022) (Online Go Forum, OpenReview) | 72 % 对抗胜率仍可破防 |
| "极限推衍" (科研 / 题材挖掘) | 10 000 – 100 000 visits | 研究者与 L19 讨论:万级可显著减少偶发失误、稳定劫争 (Life In 19x19, Life In 19x19) | 收益递减,但可作超长读秒或漏洞检测 |
所有的结果来自于:.\katago.exe benchmark -model path_to_model
因为 Katago 用的算法 MCTS 在并行运算的情况下性能会受一些影响,因此跑分分别报告推荐线程数下的每秒访问次数和最大每秒访问次数。这两个数字一般相差不大。
b18c384 网络
| 后端 | 设备 | 推荐线程数 | 每秒访问次数(在推荐线程数下) | 最大每秒访问次数(任意线程数) | 倍速 |
|---|---|---|---|---|---|
| Eigen(CPU) | Ultra 7 265 | 20 | 37.63 | 37.63 | 1.00x |
| AVX2(CPU) | Ultra 7 265 | 20 | 51.66 | 51.66 | 1.37x |
| Metal | Apple M3 Max | 12 | 348.28 | 348.28 | 9.26x |
| OpenCL | RTX 5070 | 24 | 1250.27 | ~1339 | 33.24x |
| CUDA | RTX 5070 | 48 | 2294.01 | ~2400 | 60.97x |
| TensorRT | RTX 5070 | 64 | ~3262 | ~3299 | 86.72x |
b28c512 网络
| 后端 | 设备 | 推荐线程数 | 每秒访问次数(在推荐线程数下) | 最大每秒访问次数(任意线程数) | 倍速 |
|---|---|---|---|---|---|
| Eigen(CPU) | Ultra 7 265 | 16 | 13.48 | ~15.13 | 1.00x |
| AVX2(CPU) | Ultra 7 265 | 20 | 22.05 | 22.05 | 1.64x |
| Metal | Apple M3 Max | 8 | 135.27 | ~138.61 | 10.04x |
| OpenCL | RTX 5070 | 24 | 580.03 | ~580 | 43.03x |
| CUDA | RTX 5070 | 24 | 926.79 | ~962 | 68.76x |
| TensorRT | RTX 5070 | 40 | 1397.10 | ~1424 | 103.66x |
KataGo 性能基准测试:GPU 加速分析
关键性能洞察
- GPU 加速相比 CPU 实现提供 30-100× 性能提升
- TensorRT 提供最高性能,加速比达 87-104×
- 更大的网络 (b28c512) 显示出更显著的 GPU 加速优势
不同后端和神经网络规模的性能对比。加速比以 Eigen CPU 为基准。 悬停查看详细性能指标
| Backend | Device | 网络 | 线程数 | 每秒访问次数 | 加速比 |
|---|---|---|---|---|---|
| Eigen (CPU) | Ultra 7 265 | b18c384 | 20 | 37.63 | 1× |
| AVX2 (CPU) | Ultra 7 265 | b18c384 | 20 | 51.66 | 1.37× |
| Metal | Apple M3 Max | b18c384 | 12 | 348.28 | 9.26× |
| OpenCL | RTX 5070 | b18c384 | 24 | 1250.27 | 33.24× |
| CUDA | RTX 5070 | b18c384 | 48 | 2294.01 | 60.97× |
| TensorRT | RTX 5070 | b18c384 | 64 | 3262 | 86.72× |
| Eigen (CPU) | Ultra 7 265 | b28c512 | 16 | 13.48 | 1× |
| AVX2 (CPU) | Ultra 7 265 | b28c512 | 20 | 22.05 | 1.64× |
| Metal | Apple M3 Max | b28c512 | 8 | 135.27 | 10.04× |
| OpenCL | RTX 5070 | b28c512 | 24 | 580.03 | 43.03× |
| CUDA | RTX 5070 | b28c512 | 24 | 926.79 | 68.76× |
| TensorRT | RTX 5070 | b28c512 | 40 | 1397.1 | 103.66× |
性能总结
GPU 加速对于高性能 KataGo 推理至关重要。RTX 5070 上的 TensorRT 提供最佳性能,Apple M3 Max 为 Mac 用户提供良好的 GPU 加速。CPU 实现适合休闲对弈,但不足以应对密集分析。
从跑分上来看:
- 硬件加速相比纯 CPU 实现带来显著性能提升:以 Eigen 为基准,AVX2 在两种网络上分别仅有约 1.4× 和 1.6× 的加速,而 GPU/专用加速库则轻松突破 30× 以上。
- 在 RTX 5070 上,TensorRT 提供了最高的推理吞吐量,加速比达到约 87×(b18c384)和 104×(b28c512),显著优于通用 CUDA(约 61×/69×)和 OpenCL(约 33×/43×)。
- Apple M3 Max 的 Metal 后端对比 CPU 也有约 9–10× 加速,但与 RTX 5070 的专用库相比仍存在一定差距,表明 GPU 专用推理引擎在大规模卷积计算上更具优势。
- 网络规模增大(从 b18c384 到 b28c512)时,GPU/加速库的相对加速比进一步提升,说明更重的计算任务能更充分地利用现代 GPU 的并行算力。
- CPU 在人机对弈上已经可以胜任,但分析下法的变化会较为吃力。Apple Silicon 性能基本够用,但是离独显仍有不小差距。需要最高性能则独显+TensorRT 性能断档式领先。这里不得不佩服一下老黄 😆。
总结
回顾整个装机和测试的过程,我最大的感受是如今 AI 工具在消费级硬件上的表现真的是出乎意料的强大。从 AlphaGo 问世至今算法和硬件的巨大发展使本来需要在数据中心中运行的 AI 模型可以在一个上午就部署在个人电脑上流畅运行。而现在这个进程正在 LLM 上重演。我们已经看到 2020 年 175B 的 GPT-3 在 MMLU 只有 43.9%,而 2025 年的 Qwen 3 4B 则达到接近 70%,参数量只有原来的 1⁄44,并且一张 RTX 4090 就能本地推理——充分说明算法与硬件五年间的飞跃。AI 已经颠覆了围棋界,往日的世界冠军因为找不到下棋的乐趣,选择去清华读 MBA。当每个人能在自己的设备上运行比自己更加聪明的 AI 时,给世界带来的变化又会怎样呢?
这样一思考感叹 AI 神奇的同时不可避免的有些焦虑。最简单的预测就是接下来可以程式化检验对错的任务(比如游戏,选择题,根据测试写代码),都可预见的在 RL 环境搭好之后被 AI 迅速解决并超越人类的表现。而随着多模态和算力的进步,RL 的环境将能够容纳越来越多种类的任务,甚至引入 AI 评委,让 AI 自我迭代。往极限思考一下,人不就是从出生就开始 RL 训练的具身智能吗?😜 所以 AI 完全替代人类的瓶颈在于: (1) RL 环境还无法模拟地球 OL (2)AI 模型无法复刻人类感官的输入 (3)模型训练缺乏人类动辄数十年的长文本上下文数据。
由此可见,短期内的理性的应对有:1)当训练这些 AI 的人 2)当使用这些 AI 的人 3)离这些要被颠覆的行当远远的 😆。
中长期的应对,则在于发展自己的跨任务/跨行业/跨领域经验,去扎根 AI 缺乏训练数据和训练环境的独特复合领域。
人对恐惧来源于未知 - 对于未来的不确定性。在 AI 带来大变革的时代,最能让人安心的是快速学习的能力 - 毕竟 AI 在可见的未来还是需要有人去训练,去维护,去操作的。
如果你对 AI 的发展有自己的思考,或对本文装机方案有任何疑问或建议,欢迎留言交流~
期待与你在下篇博文中再见!下一篇计划写 CMU Intro to Deep Learning 课程打 Kaggle 比赛的探索 🚀